[This might be more a “note to self” than anything else and might not be immediately clear. If this one goes over your head on the first pass – read it once more ;-)]
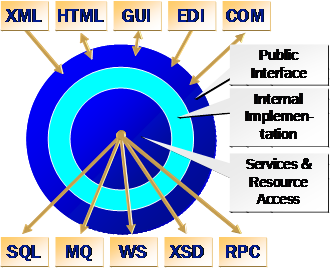 Fellow German RD Ralf Westphal is figuring out layers and data access. The “onion” he has in a recent article on his blog resembles the notation that Steve Swartz and I introduced for the Scalable Applications Tour 2003. (See picture; get the full layers deck from Microsoft’s download site if you don’t have it already)
Fellow German RD Ralf Westphal is figuring out layers and data access. The “onion” he has in a recent article on his blog resembles the notation that Steve Swartz and I introduced for the Scalable Applications Tour 2003. (See picture; get the full layers deck from Microsoft’s download site if you don’t have it already)
What Ralf describes with his “high level resource access” public interface encapsulation is in fact a “data service” as per our definition. To boot, we consider literally every unit in a program (function, class, module, service, application, system) as having three layers: the outermost layer is the publicly accessible interface, the inner layer is the hidden internal implementation and the innermost layer hides and abstracts services and resource access. The concrete implementation of this model depends on the type of unit you are dealing with. A class has public methods as public interface, protected/private methods as internal implementation and uses “new” or a factory indirection to construct references to its resource providers. A SQL database has stored procedures and views as public interface, tables and indexes as internal implementation and the resource access is the database engine itself. It goes much further than that, but I don’t want to get carried away here.
A data service is a layered unit that specializes in acquiring, storing, caching or otherwise dealing with data as appropriate to a certain scope of data items. By autonomy rules, data services do not only hide the data access methods, but also any of these characteristics. The service consumer can walk up to a data service and make a call to acquire some data and it is the data service’s responsibility to decide how that task is best fulfilled. Data might be returned from a cache, aggregated from a set of downstream services or directly acquired from a resource. Delegating resource access to autonomous services instead of “just” encapsulating it with a layer abstraction allows for several implementations of the same data service contract. One of the alternate implementations might live close to the master data copy, another might be sitting on a replica with remote update capability and yet another one may implement data partitioning across a cluster of storage services. Which variant of such a choice of data services is used for a specific environment then becomes a matter of the deployment-time wiring of the system.
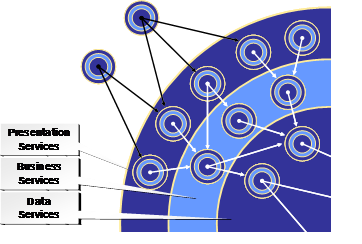 Data services are the resource access layer of the “onion” model on the next higher level of abstraction. The public interface consists of presentation services (which render external data presentations of all sorts, not only human interaction), the internal implementation is made up of business services that implement the core of the application and the resource access are said data services. On the next higher level of abstraction, presentation services may very well play the role of data services to other services. And so it all repeats.
Data services are the resource access layer of the “onion” model on the next higher level of abstraction. The public interface consists of presentation services (which render external data presentations of all sorts, not only human interaction), the internal implementation is made up of business services that implement the core of the application and the resource access are said data services. On the next higher level of abstraction, presentation services may very well play the role of data services to other services. And so it all repeats.
Now … Ralf says he thinks that the abstraction model works wonderfully for pulling chunks of data from underlying layers, but he’s very concerned about streaming data and large data sets – and uses reporting as a concrete example.
Now, I consider data consolidation (which reporting is) an inherent functionality of the data store technology and hence I am not at all agreeing with any part of the “read millions of records into Crystal Reports” story. A reporting rendering tool shall get pre-consolidated, pre-calculated data and turn that into a funky document; it should not consolidate data. Also, Ralf’s proposed delivery of data to a reporting engine in chunks doesn’t avoid that you’ll likely end up having to co-locate all received data into memory or onto disk to actually run the consolidation and reporting job --- in which case you end up where you started. But that’s not the point here.
Ralf says that for very large amounts of data or data streams, pull must change to push and the resource access layer must spoon-feed the business implementation (reporting service in his case) chunks of data at a time. Yes! Right on!
What Ralf leaves a bit in the fog is really how the reporting engine learns of a new reporting job, where and how results of the engine are being delivered and how he plans to deal with concurrency. Unfortunately, Ralf doesn’t mention context and how it is established and also doesn’t loop his solution back to the layering model he found. Also, the reporting service he’s describing doesn’t seem very flexible as it cannot perform autonomous data acquisition, but is absolutely dependent on being fed by the app – which might create an undesirable tightly coupled dependency between the feeder and a concrete report target.
The reporting service shall be autonomous and must be able to do its own data acquisition. It must be able to “pull” in the sense that it must be able to proactively initiate 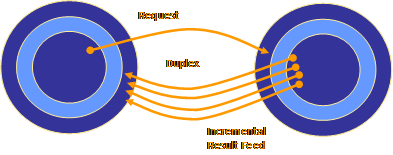 requests to data providers. At the same time, Ralf is right that the request result should be pushed to the reporting service, especially if the result set is very large.
requests to data providers. At the same time, Ralf is right that the request result should be pushed to the reporting service, especially if the result set is very large.
Is that a contradiction? Does that require a different architecture? I’d say that we can’t allow very large data sets to break the fundamental layering model or that we should have to rethink the overall architectural structure in their presence. What’s needed is simply a message/call exchange pattern between the reporting service and the underlying data service that is not request/response, but duplex and which allows the callee to incrementally bubble up results to the caller. Duplex is the service-oriented equivalent of a callback interface with the difference that it’s not based on a (marshaled) interface pointer but rather on a more abstract context or correlation identifier (which might or might not be a session cookie). The requestor invokes the data service and provides a “reply-to” endpoint reference referencing itself (wsa:ReplyTo/wsa:Address), containing a correlation cookie identifying the originator context (wsa:ReplyTo/wsa:ReferenceProperties), and identifying an implemented port-type (wsa:ReplyTo/wsa:PortType) for which the data service knows how to feed back results. The port-type definition is essential, because the data service might know quite a few different port-types it can feed data to – in the given case it might be a port-type defined and exposed by the reporting service. [WS-Addressing is Total Goodness™]. What’s noteworthy regarding the mapping of duplex communication to the presented layering model is that the request originates from within the resource access layer, but the results for the requests are always delivered at the public interface.
The second fundamental difference to callbacks is that the request and all replies are typically delivered as one-way messages and hence doesn’t block any resources (threads) on the respective caller’s end.
For chunked data delivery, the callee makes repeated calls/sends messages to the “reply-to” destination and sends an appropriate termination message or makes a termination call when the request has been fulfilled. For streaming data delivery, the callee opens a streaming channel to the “reply-to” destination (something like a plain socket, TCP/DIME or – in the future -- Indigo’s TCP streaming transport) and just pumps a very long, continuous message.
Bottom line: Sometimes pull is good, sometimes push is good and duplex fits it all back into a consistent model.