Ralf Westphal responded to this and there are really just two sentences that I’d like to pick out from Ralf’s response because that allows me to go a quite a bit deeper into the data services idea and might help to further clarify what I understand as a service oriented approach to data and resource management. Ralf says: There is no necessity to put data access into a service and deploy it pretty far away from its clients. Sometimes is might make sense, sometimes it doesn’t.
I like patterns that eliminate that sort of doubt and which allow one to say “data services always make sense”.
Co-locating data acquisition and storage with business rules inside a service makes absolute sense if all accessed data can be assumed to be co-located on the same store and has similar characteristics with regards to the timely accuracy the data must have. In all other cases, it’s very beneficial to move data access into a separate, autonomous data service and as I’ll explain here, the design can be made so flexible that the data service consumer won’t even notice radical architectural changes to how data is stored. I will show three quite large scenarios to help illustrating what I mean: A federated warehouse system, a partitioned customer data storage system and a master/replica catalog system.
The central question that I want to answer is: Why would you want delegate data acquisition and storage to dedicated services? The short answer is: Because data doesn’t always live in a single place and not all data is alike.
Here the long answer:
The Warehouse
 The Warehouse Inventory Service (WIS) holds data about all
the goods/items that are stored in warehouse. It’s a data service in the
sense that it manages the records (quantity in stock, reorder levels, items on
back order) for the individual goods, performs some simplistic accounting-like
work to allocate pools of items to orders, but it doesn’t really contain
any sophisticated business rules. The services implementing the supply order
process and the order fulfillment process for customer orders implement such
business rules – the warehouse service just keeps data records.
The Warehouse Inventory Service (WIS) holds data about all
the goods/items that are stored in warehouse. It’s a data service in the
sense that it manages the records (quantity in stock, reorder levels, items on
back order) for the individual goods, performs some simplistic accounting-like
work to allocate pools of items to orders, but it doesn’t really contain
any sophisticated business rules. The services implementing the supply order
process and the order fulfillment process for customer orders implement such
business rules – the warehouse service just keeps data records.
 The public interface [“Explicit Boundary” SOA
tenet] for this service is governed by one (or a set of) WSDL portType(s),
which define(s) a set of actions and message exchanges that the service implements
and understands [“Shared Contract” SOA tenet]. Complementary is a deployment-dependent
policy definition for the service, which describes several assertions about the
Security and QoS requirements the service makes [“Policy” SOA tenet].
The public interface [“Explicit Boundary” SOA
tenet] for this service is governed by one (or a set of) WSDL portType(s),
which define(s) a set of actions and message exchanges that the service implements
and understands [“Shared Contract” SOA tenet]. Complementary is a deployment-dependent
policy definition for the service, which describes several assertions about the
Security and QoS requirements the service makes [“Policy” SOA tenet].
The WIS controls its own, isolated store over which it has exclusive control and the only way that others can get at the content of that data store is through actions available on the public interface of the service [“Autonomy” SOA tenet].
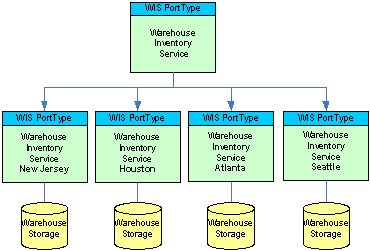
Now let’s say the company running the system is a bit bigger and has a central website (of which replicas might be hosted in several locations) and has multiple warehouses from where items can be delivered. So now, we are putting a total of four instances of WIS into our data centers at the warehouses in New Jersey, Houston, Atlanta and Seattle. The services need to live there, because only the people on site can effectively manage the “shelf/database relationship”. So how does that impact the order fulfillment system that used to talk to the “simple” WIS? It doesn’t, because we can build a dispatcher service implementing the very same portType that accepts order information, looks at the order’s shipping address and routes the allocation requests to the warehouse closest to the shipping destination. In fact now, the formerly “dumb” WIS can be outfitted with some more sophisticated rules that allow to split or to shift the allocation of items to orders across or between warehouses to limit freight cost or ensure the earliest possible delivery in case the preferred warehouse is out of stock for a certain item. Still, from the perspective of the service consumer, the WIS implementation is still just a data service. All that additional complexity is hidden in the underlying “service tree”.
While all the services implement the very same portType, their service policies may differ significantly. Authentication may require certificates for one warehouse and some other token for another warehouse. The connection to some warehouses might be done through a typically rock-solid reliable direct leased line, while another is reached through a less-than-optimal Internet tunnel, which impacts the application-level demand for the reliable messaging assurances. All these aspects are deployment specific and hence made an external deployment-time choice. That’s why WS-Policy exists.
The Customer Data Storage
 This scenario for the Customer Data Storage Service (CDS) starts
as simple as the Warehouse Inventory scenario and with a single service. The
design principles are the same.
This scenario for the Customer Data Storage Service (CDS) starts
as simple as the Warehouse Inventory scenario and with a single service. The
design principles are the same.
Now let’s assume we’re running a quite sophisticated e-commerce
site where customers can customize quite a few aspects of the site, can store and
reload shopping carts, make personal annotations on items, and can review 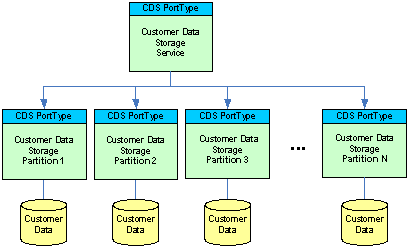 their own order history. Let’s also assume that we’re
pretty aggressively tracking what they look at, what their search keywords are
and also what items they put into any shopping cart so that we can show them a very
personalized selection of goods that precisely matches their interest profile. Let’s
say that all-in-all, we need to have storage space of about 2Mbytes for the cumulative
profile/tracking data of each customer. And we happen to have 2 million
customers. Even in the Gigabyte age, ~4mln Mbytes (4TB) is quite a bit of data payload
to manage in a read/write access database that should be reasonably responsive.
their own order history. Let’s also assume that we’re
pretty aggressively tracking what they look at, what their search keywords are
and also what items they put into any shopping cart so that we can show them a very
personalized selection of goods that precisely matches their interest profile. Let’s
say that all-in-all, we need to have storage space of about 2Mbytes for the cumulative
profile/tracking data of each customer. And we happen to have 2 million
customers. Even in the Gigabyte age, ~4mln Mbytes (4TB) is quite a bit of data payload
to manage in a read/write access database that should be reasonably responsive.
So, the solution is to partition the customer data across an array of smaller (cheaper!) machines that each holds a bucket of customer records. With that we’re also eliminating the co-location assumption.
As in the warehouse case, we are putting a dispatcher service implementing
the very same CDS portType on top of the partitioned data service array and
therefore hide the storage strategy re-architecture from the service consumers entirely.
With this application-level partitioning strategy (and a set of auxiliary
service to manage partitions that I am not discussing here), we could scale
this up to 2 billion customers and still have an appropriate architecture. Mind
that we can have any number of dispatcher instances as long as they implement
the same rules for how to route requests to partitions. Strategies for this are
a direct partition reference in the customer identifier or a locator service
sitting on 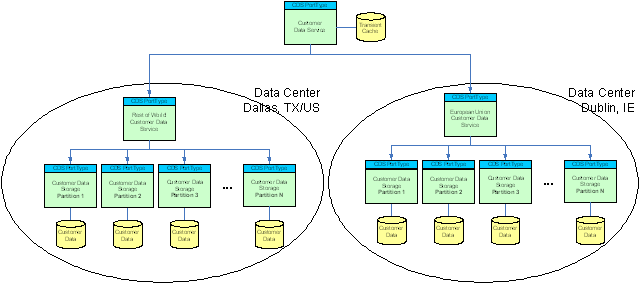 a customer/machine lookup dictionary.
a customer/machine lookup dictionary.
Now you might say “my database engine does this for me”. Yes, so-called “shared-nothing” clustering techniques do exist on the database level for a while now, but the following addition to the scenario mandates putting more logic into the dispatching and allocation service than – for instance – SQL Server’s “distributed partitioned views” are ready to deal with.
What I am adding to the picture is the European Union’s Data Privacy Directive. Very simplified, the EU directives and regulations it is illegal to permanently store personal data of EU citizens outside EU territory, unless the storage operator and the legislation governing the operator complies with the respective “Safe Harbor” regulations spelled out in these EU rules.
So let’s say we’re a tiny little bit evil and want to treat EU data according to EU rules, but be more “relaxed” about data privacy for the rest of the world. Hence, we permanently store all EU customer data in a data center near Dublin, Ireland and the data for the rest of the world in a data center in Dallas, TX (not making any implications here).
In that case, we’re adding yet another service on top of the unaltered partitioning architecture that implements the same CDS contract and which internally implements the appropriate data routing and service access rules. Those rules which will most likely be based on some location code embedded in the customer identifier (“E1223344” vs. “U1223344”). Based on these rules, requests are dispatched to the right data center. To improve performance and avoid having to data travel along the complete path repeatedly or in small chunks during an interactive session with the customer (customer is logged into the web site), the dispatcher service might choose to have a temporary, non-permanent cache for customer data that is filled with a single request and allows quicker and repeat access to customer data. Changes to the customer’s data that result from the interactive session can later be replicated out to the remote permanent storage.
Again, the service consumer doesn’t really need to know about these massive architectural changes in the underlying data services tree. It only talks to a service that understands a well-known contract.
The Catalog System
 Same picture to boot with and the same rules: Here we have
a simple service fronting a catalog database. If you have millions of catalog
items with customer reviews, pictures, audio and/or video clips, you might
chose to partition this just like we did with the customer data.
Same picture to boot with and the same rules: Here we have
a simple service fronting a catalog database. If you have millions of catalog
items with customer reviews, pictures, audio and/or video clips, you might
chose to partition this just like we did with the customer data.
If you have different catalogs depending on the markets you are selling into (for instance German-language books for Austria, Switzerland and Germany), you might want to partition by location just as in the warehouse scenario.
One thing that’s very special about catalog data is that very much of
it rarely ever changes. Reviews are added, 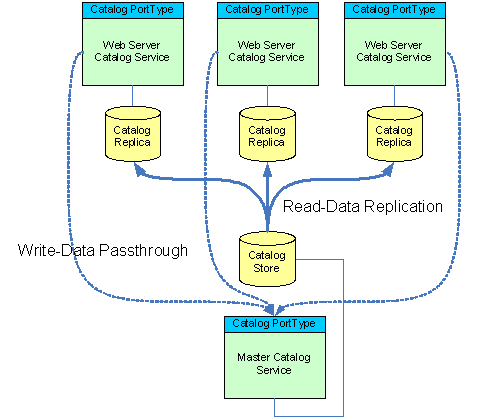 media might be
added, but except for corrections, the title, author, ISBN number and content
summary for a book really doesn’t ever change as long as the book is kept
in the catalog. Such data is essentially “insert once, change never”.
It’s read-only for all practical purposes.
media might be
added, but except for corrections, the title, author, ISBN number and content
summary for a book really doesn’t ever change as long as the book is kept
in the catalog. Such data is essentially “insert once, change never”.
It’s read-only for all practical purposes.
What’s wonderful about read-only data is that you can replicate it, cache it, move it close to the consumer and pre-index it. You’re expecting that a lot of people will search for items with “Christmas” in the item description come November? Instead of running a full text search every time, run that query once, save the result set in an extra table and have the stored procedure running the “QueryByItemDescription” activity simply return the entire table if it sees that keyword. Read-only data is optimization heaven.
Also, for catalog data, timeliness is not a great concern. If a customer review or a correction isn’t immediately reflected on the presentation surface, but only 30 minutes or 3 hours after is has been added to the master catalog, it doesn’t do any harm as long as the individual adding such information is sufficiently informed of such a delay.
So what we can do to with the catalog is to periodically (every few hours or even just twice a week) consolidate, pre-index and then propagate the master catalog data to distributed read-only replicas. The data services fronting the replicas will satisfy all read operations from the local store and will delegate all write operations directly (passthrough) to the master catalog service. They might choose to update their local replica to reflect those changes immediately, but that would preclude editorial or validation rules that might be enforced by the master catalog service.
So there you have it. What I’ve described here is the net effect of sticking to SOA rules.
· Shared Contract: Any number of services can implement the same contract (although the concrete implementation, purpose and hence their type differ). Layering contract-compatible services with gradually increasing levels of abstractions and refining rules over existing services creates very clear and simple designs that help you scale and distribute data very well
· Explicit Boundaries: Forbidding foreign access or even knowledge about service internals allows radical changes inside and “underneath” services.
· Autonomy allows for data partitioning and data access optimization and avoids “tight coupling in the backend”.
· Policy: Separating out policy from the service/message contract allows flexible deployment of the compatible services across a variety of security and trust scenarios and also allows for dynamic adaptation to “far” or “near” communications paths by mandating certain QoS properties such as reliable messaging.
Service-Orientation is most useful if you don’t consider it as just another technique or tool, but embrace it as a paradigm. And very little of this thinking has to do with SOAP or XML. SOAP and XML are indeed just tools.