

Two weeks ago, during a very busy conference week that saw CNCF KubeCon, Hannover Messe, and FabCon all take place simultaneously, with me being in Hannover, the CNCF Serverless Working Group that I am part of, released the first release candidate of xRegistry. This is a significant milestone for the project, and I wanted to take a moment to share what xRegistry is, why it matters, and what’s next for the project.
Origins
The xRegistry project is a sibling project of CNCF CloudEvents, produced by the same working group and, for the most part, the same people.
After the CloudEvents 1.0 release in 2019, the working group vowed to avoid breaking changes and give CloudEvents time and stability for adoption. Since then, we've relased 1.0.1, 1.0.2 as "errata" releases with 1.0.3 being the current "work in progress" version for further corrections. None of those releases made any substantial changes to the core spec, but we've made some additions and a few tweaks in the attribute extensions and transport binding and event format areas.
Observations
As folks were starting to implement CloudEvents in serious projects, we made a few observations:
First, the data section of a CloudEvent generally contains structured data that is serialized in a specific encoding (JSON, XML, Avro, Protobuf, etc.). Some of these encodings require schema documents to be able to even understand the encoded data, as it is the case for Avro and Protobuf.
For the CloudEvents envelope, we had a formal binding and schema for Avro in the v1.0 release and added a Protobuf binding in the v1.0.1 release.
Since our goal for CloudEvents is to promote interoperability and vendor neutrality, the question quickly arose on how to enable applications to share schema documents for the data section of a CloudEvent if developers wanted to use one of these efficient and binary but schema-dependent encodings. Some schema registry products/projects were around at the time, but there were no vendor-neutral specifications or standards for them.
Second, we observed that when applications were raising CloudEvents, the way how those CloudEvents were made known to developers was generally through prose and examples in documentation. There was no formal, machine readable way to declare and document the shape of a CloudEvent: What is the type value, what does the source value look like, what are the required and optional standards and extension attributes for this specific event type, and what is the schema for the data section?
Third, we heard that it would be very useful for developer tools to be able to know about event sources and sinks that exist in their ecosystem, so that applications can be built that can react to events from those sources and send events to those sinks.
Explorations
As a result, we started some exploratory work in the working group on "schema registry" and "discovery". Mike Helmick from LinkedIn submitted a "Discovery API" in March 2020. I proposed a "Schema registry API" in May 2020.
After the chaos of the pandemic, we starts a sub-working group to make progress in that area and to explore the three aspects I mentioned above: How do I share schema? How do I catalog and declare events? How do I discover event sinks and sources?
As we made progress on this, we realized that these three sub-projects were so interdependent that it would be beneficial if these three registries could be, optionally, collocated behind a single API facade. We also realized that an API alone would not be sufficient, but that we would also want for the same metadata to be available in document format such that it could be exchanged or used to drive tools like code generators.
As we then worked on aligning the APIs, we found that we had a lot of commonalities across the three registries, and that we could actually build a single registry API that would be able to serve all three use cases, whereby the differences could be expressed in a lightweight configuration-model that the registry server could use to adapt the API to the specific use case.
Once we arrived at this conclusion, we also realized that we could use the same configuration model for any other metadata registry use case. Thus, the extensible registry, xRegistry, came into being.
xRegistry
The core specification of xRegistry describes a document format and a REST API that can be used to manage and interact with metadata registries. The core specification also defines the configuration model that allows to define the registry behavior and the specific sub-registry metadata content. If the hasdocument model attribute is true for a resource type, the registry acts as a document store with accompanying metadata. If the value is false, it's a pure structured data store.
A key principle across xRegistry is that all resources are managed inside of groups. A group is a logical collection of resources that can be used for organization and/or access control. It's possible to cross-reference resources between groups, such that one resource can logically occur in multiple groups.
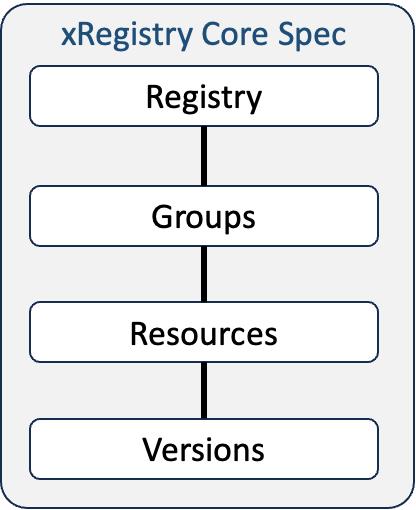
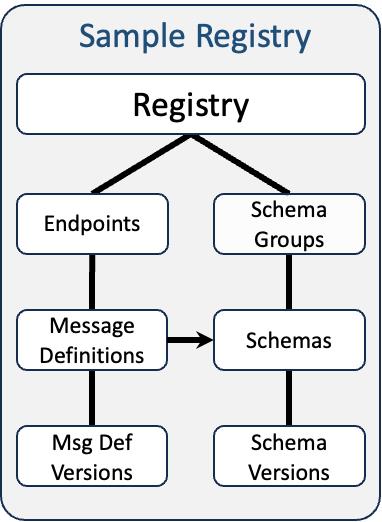
The schema specification defines a sub-registry for serialization and validation schema documents. It enables the versioning model of xRegistry such that all versions of a schema document are kept in the registry and can be referenced by their version. The registry has a notion of a "default" schema version, which is the one that is returned when no version is specified. The registry is also able to maintain version lineage information and provides a compatibility policy mechanism that implementations can enforce.
The message definitions specification defines a sub-registry for event and message definitions. Initially, we only allowed for declaring CloudEvents, but we quickly realized that declaring metadata for all other major messaging protocols (AMQP, MQTT, Kafka, etc.) would be useful as well, even in combination with CloudEvents. The message definition registry allows declaring both protocol-specific metadata and envelope metadata for events, including field-level descriptions and type information. String-typed metadata fields can be declared as being URI templates, which allows declaring placeholders and simple filter wildcards. Each message definition can be linked to a schema from the schema registry or can embed a local schema for the payload.
The grouping mechanism of xRegistry requires that message definitions are grouped, which is a very convenient way to organize message definitions that apply to a specific communication channel. A message definition group can therefore form a logical interface for a specific communication channel, e.g. a Kafka topic or an AMQP queue.
The endpoint registry specification defines a sub-registry for event sources (consumer endpoints) and sinks (publisher endpoints) as well as for "subscriber endpoints" that advertise protocol-specific endpoints to establish a consumer relationship, e.g. the address of a Kafka broker to create a new consumer group. The specification explicitly defines protocol-specific metadata for various protocols to help with interoperability. Each endpoint can reference one or more message definition groups from the message definition registry. Each endpoint also forms it own message definition group, meaning it can embed one or more message definitions that are specific to the endpoint.
There are some examples of the document form of xRegistry in the samples section of the project repository. When you look through those, you will likely find that while the specification documents are very detailed, concrete document examples are quite simple to read. The schemastore.org example shows an xRegistry overlay for the entire schema collection of that site.
There is chatter about xRegistry competing with AsyncAPI. I'd say the efforts have very different goals. The xRegistry message definition registry's "message groups" yield a similar concept to AsyncAPI channels, but xRegistry does not define a model for how message flows and channels relate. xRegistry is a metadata catalog first and foremost; its ability to define contracts for channels is a byproduct of its structure.
How is this useful to me? Right now?
Follow the links and study the following three examples of xRegistry documents:
What you'll find is that these documents are formal definitions of what flows over a Kafka topic, a set of MQTT topics and a generic CloudEvents channel. If you are using Kafka or MQTT or AMQP or NATS or HTTP WebHooks or CloudEvents today, xRegistry gives you an instantly useful way to formally document what's going on in that Kafka topic and in that AMQP queue. Which headers or which key identify which kind of message and what schema is associated with it.
In a way, this is like WSDL (there's an old term!) or OpenAPI for asynchronous eventing/messaging channels, but for the most popular protocol messages and envelopes and schemas and encodings all at once. Instantly useful as a documentation tool.
A complete reference implementation of the xRegistry API is part of the project, which means that you can also stand up a server already to manage your metadata. Front this server with a proxy or API gateway that handles authorization and you've got a very flexible metadata solution.
Down the road, and that ought not to shock you knowing that I work at Microsoft, these formal declarations of what flows on a messaging/eventing channel will become very concretely useful, because you'll be able to tell Azure and Fabric about your channels with them and our tooling will be able to help you a lot better with wrangling your fast moving data.
What's Next?
Now, and this leads me to the "what's next" part, I do think there's a need for becoming formal about relationships between channels and for defining message flows. I do not think that a request/response and client/server "API" notion is the right starting point and approach for that.
We are looking at a future of collaborating agentic applications that are strung together through asynchronous communication channels. An agent is getting a job to handle and enlists a number of other agents to help with that job. The work on that job may take a long time and results may be produced progressively over multiple responses or with intermediate states change reports.
The ISO 20022 set of standards for financial services defines a message flow diagram for each described business process and associated set of message definitions. These message flows are not APIs, they are often fairly complex, multi-party document exchanges.
The ITU Z.120 "Message Sequence Chart" standard is fairly ancient and a long and arduous read, but it is good prior art to look at for a formalism to describe message flows. I believe that "sequence diagrams as a contract" is a missing piece in the puzzle of strongly-typed, interoperable, and formally defined asynchronous communication.
xRegistry's endpoint definitions with associated message definition groups and schemas are well suited to declare the "instance contracts" in the message sequence chart shown below, but we need an extra formal layer to describe the message flow itself.
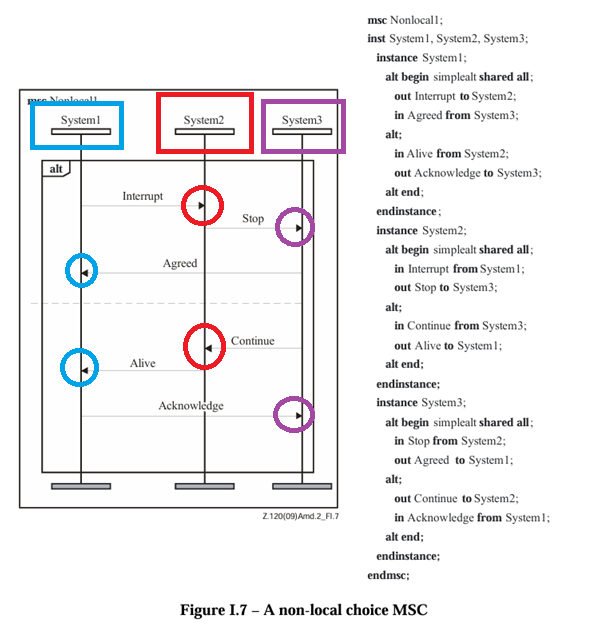
From ITU Z.120
Whatever that contract document will look like, it's metadata and therefore will be managable inside of xRegistry.