This blog post discusses the considerations behind the introduction of a logical addressing model for the AMQP Addressing specification (which is equivalently applicable to other protocols including HTTP) that coexists and integrates with the common IP/DNS addressing model and non-IP networks. Logical addressing can be used to form overlay networks spanning multiple and mutually isolated networks. The model allows for all actors of a system to be consistently addressed, irrespective of whether they reside in edge, fog, or cloud, and enables application-layer algorithmic routing traversing traditional network boundaries. For instance, a sensor inside a drive inside a component of a factory machine could be directly addressed by a cloud-based maintenance support system, in spite of the required route potentially traversing buses and gateways and address translations and more gateways that prevent direct IP-level addressability.
Let’s start with the Internet we know:

The Internet uses “IP”, the Internet Protocol. Network participants have unique hardware-identifiers for communicating at the lowest level. Those identifiers are mapped to addresses on the IP network. Routers know and coordinate how to get from one place on the IP network to another, with traffic often being guided along a route, traversing multiple routers. UDP, the User Datagram Protocol, is a transport layer for moving individual packets between IP peers (or to IP groups). Different uses of UDP between IP peers can be de-/multiplexed by using different port numbers. TCP, the Transmission Control Protocol, is the most common transport layer for moving stream-oriented data between IP peers, also allows port-based multiplexing. On top of TCP, there’s a plethora of application protocols, but most prominently HTTP, for applications to layer formatting and semantics over the raw streams TCP provides. For users and applications not to have to deal with raw addresses, but also to provide flexibility in directing and redirecting connections, IP addresses are mapped to names with the Domain Name System, DNS. A party interested in communicating with another, knows a name, resolves it to an address, and then opens a connection on a supported transport layer port, and overlaid with a supported application protocol. Both parties then talk.
At least that’s the theory of the Internet you know.
The Internet you use is a tangled hodgepodge of tricks and bridges and tunnels and secret pathways and more tricks that all try to get around the facts that the Internet’s structure is fairly static and that the vast majority of the Internet participants are not even on the Internet, but rather attached through some sort of intermediary gateway.
Hostland and Userland
The Internet is split into Hostland, with approximately 1 billion named hosts who actively listen for inbound connections being advertised in DNS, and Userland with coming up on 4 billion individuals with Internet access, and somewhere between 10 and 20 billion connected “Internet of Things” devices, depending on who’s statistics you choose to believe.
Participants in Hostland have publicly reachable IP addresses allowing them to be targeted with connection requests, while those in Userland generally do not. Userland continues to grow explosively, Hostland growth has leveled off in the last several years.
Some lament that this split of the network into the “full” Hostland participants on the inside and the attached and constrained Userland participants on the periphery is the fault of the address space restrictions of Version 4 of the Internet Protocol, which only allows for about 3.7 billion public unicast addresses and therefore far fewer than the number of devices already connected. While that claim is technically true, the growth of Version 6 of the Internet Protocol that vastly expands the address space and has been very slow over nearly two decades of availability and has been primarily fueled by the network operators’ own need for expanded address spaces rather than by application writers clamoring for it. IPv6 adoption is inevitable, but still only covers a minority of participants.
A reason for the anemic adoption might be that a key promise of IPv6, stable and public addressability of every device on the network, is not all that desirable.
The Userland isolation of devices in private networks and behind Network Address Translators (NAT) or behind “carrier grade” NATs in wireless networks is not only a way to expand the available address space, it’s also a practical way to keep unwanted inbound traffic away from potentially vulnerable devices and provides easy and effective segmentation of private realms with lower security demands from the toxic waste pool that is the public network. It’s worth recalling that the term “Internet” has always described a network of networks, so this by no means an accident. Dynamically assigned addresses also help with protecting user privacy. As addresses change, the network address provides no stable anchor for tracking. The indirection and masquerading provided by Network Address Translators is indeed a feature.
Yet, nearly every connected consumer device receives “push” messages addressed to it, and many of the billions of IoT devices can be remote controlled across the network. And, of course, all of us are individually addressable and reachable through Instant Messengers with quasi-real time delivery of text and media, and often simultaneously on different devices. How so?
Because Userland is largely and intentionally out of reach for connections originating from Hostland, there are myriad ways to turn the tables and have Userland clients connect out to endpoints in Hostland and then hold one to those connections, so that messages can be sent back to the Userland clients as the need arises. When the connection collapses, the Userland client connects again to the same endpoint and using the same identity, reestablishing the IP route through Network Address Translators and Firewalls. I’ve previously written about that principle under the Service Assisted Communication moniker.
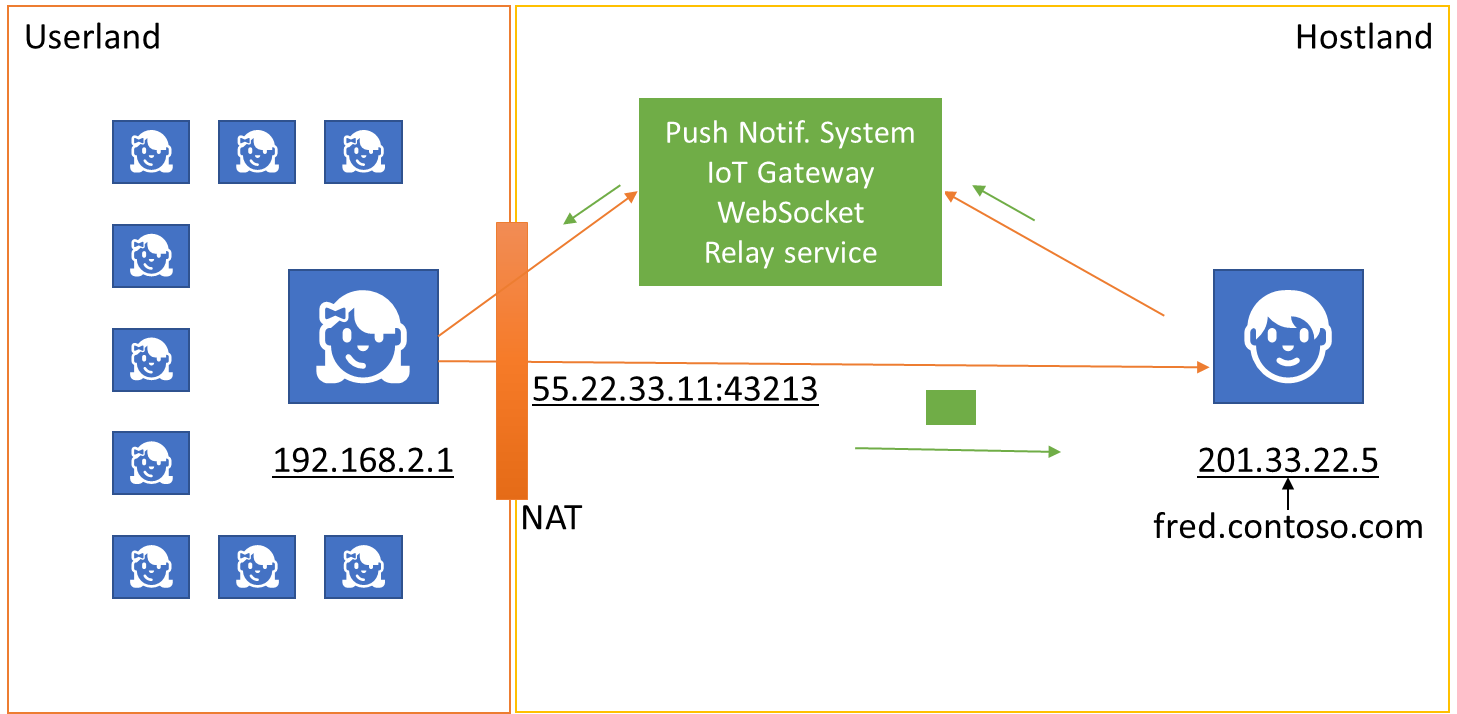
The pop-up notification channels of your iOS or Android shell, of your Windows PCs, and your browser all use that principle. Many browser applications and mobile apps establish private callback channels for the server to push information back to the client through using Websockets or the HTTP/2 notification channel. IoT platforms that anticipate sparse connectivity realize such routes through intermediary queues that hold information destined to the device that gets picked up as the device gets a chance.
There are IoT gateways in the field and IoT hubs in the cloud, there are push notification systems and pub-sub infrastructures that feed into push notification systems, there are “real-time web” and “real-time stream” routing services, and there are message brokers and concentrators of various kinds – and there are many varieties of each of these infrastructure types, each with their own idiosyncratic ways of doing things, and each with its own notion of addressing, and each using tremendous resources for managing routing and connections. And they all aim to solve the same problem: Reaching Userland.
The extreme IPv6 proponents’ idea to simplify matters is to tear down the boundaries, give everything a global IPv6 address, and let every device be a host: Hostland everywhere.
A more secure path towards a unified addressing and routing model that does away with the idiosyncrasies of a myriad hacks is to embrace the boundaries and make them a feature: Userland everywhere.
Boundaries and Monocultures
The alternative to clinging to the dream of a unified, global address and routing space for IP and its overlaid transport protocols, is to embrace private IP networks as islands, each with its own set of policies. Some private networks may only allow known participants, some allow for visiting guests. Participants, in turn, may roam across different private networks. The Internet is the federation fabric that interconnects those islands. It’s not a network for clients to use, but it’s also not a network for hosts to use: All clients and all hosts, indeed all application endpoints, must reside on private networks, in Userland.
That may initially sound extreme from the perspective of the idealized and simple picture of the Internet painted at the beginning of this article but is rather close to current practice.
As discussed, clients typically reside in private networks. But hosts increasingly also reside in private networks. This is nearly always true if the host is cloud and/or container based and bound to a NAT with a public IP. It is also nearly always true, inside or outside of cloud and containers, when the host(s) require a load balancer or a fronting reverse proxy or an API management gateway.
In cloud environments, the practice of zoning applications in virtual networks with private address spaces and having tight network-level access rules for all dependency services, has become a security best practice to reduce an application’s attack surface area. The external-facing endpoint NAT or load balancer is an explicitly managed resource federated with the application.
The goal of reduction of management complexity is also fueling the trend towards protocol monoculture. Unless services find a way to use HTTP/HTTPS or multiplex over their TCP ports (80/443) with the help of WebSockets, communication through corporate gateways is today often impossible because of the respective IT departments are already overwhelmed with managing and supervising web traffic for malware, intrusion, exfiltration, and access control, and have little interest in taking on further risk by opening ports for protocols they don’t have expertise or tooling for.
That is not necessarily a sign of HTTP’s fitness for all the world’s use-cases, but rather the capitulation of corporate IT facing the complexity of thousands of different protocols. There are many corporate environments from which the Internet outside of TCP 80/433 simply does not exist, by choice.
Magically Ubiquitous Databases
An interesting (retro) trend in application architecture is for applications to delegate distribution of information and communication of commands and even execution of commands to some form of underlying database. Making one database the center of everything had been fairly common practice in simple local applications of the initial client/server wave in the 1990s. Many client pre-web applications would only ever talk to the database, sometimes by the thousands, and handle any cross-instance coordination that way, with most logic handled locally. Only the dimensions of the global networked solutions, in both geographic distribution and scale, made it necessary for applications themselves to turn to the network as an active element.
Making a database the anchor point for an application is enormously comfortable, because there’s only one network dependency to connect to, and all further addressing of entities is purely logical within the realm of that database.
Today, some major cloud vendors now offer global database systems that provide multiple API personas and configurable consistently levels for global multi-datacenter replication, so that a data record can be added and present in dozens of global locations within milliseconds. And of course there’s an army of database experts that build sophisticated, bespoke federations of databases that selectively replicate information across the globe on behalf of applications.
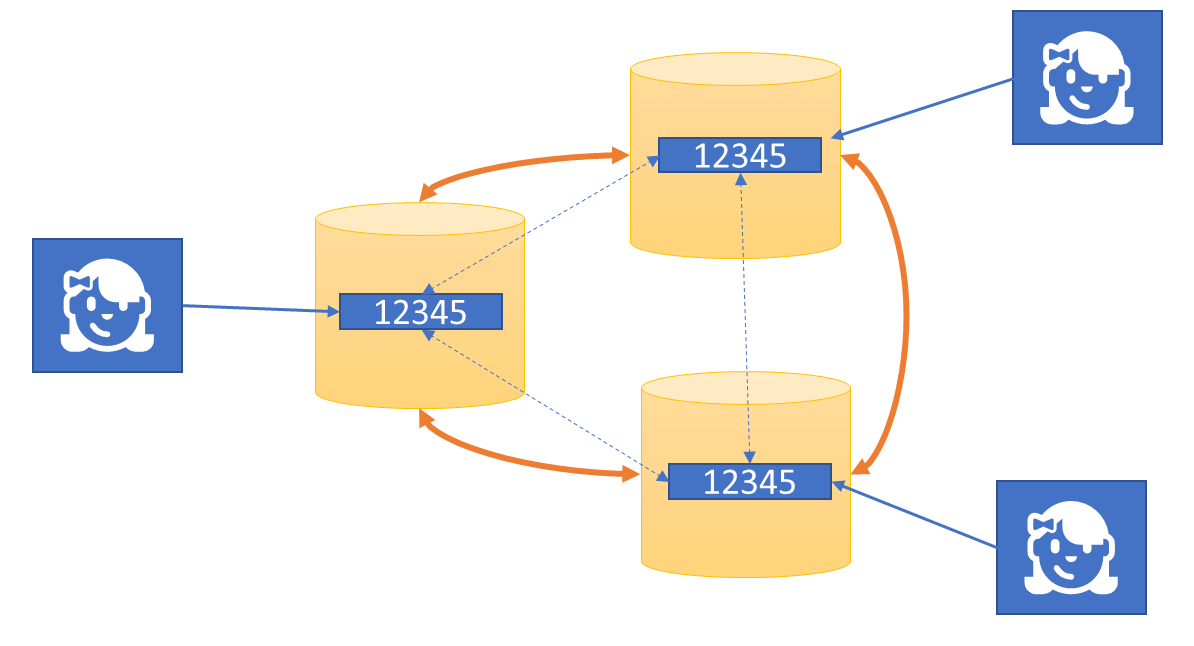
Using such a database system allows for enormously powerful planet-scale datacenter applications without the solution developers having to deal directly with the complexities of intra-application communications.
The tradeoff of this model is that data replication is a very coarse grained and undifferentiated way of communication; it works well for when globally distributed instances of the same application are clustered around the respective replicas, like in a web application scenario. It’s not a good match for dealing with torrents of data that need to be analyzed and reduced in real-time or for heterogenous application environments where mobile and edge applications need far more targeted data communication.
The most extreme new trend in this area is the blockchain. A blockchain is effectively an append-only log database whereby the order of records is cryptographically enforced. Since all records are read-only after having been added to the blockchain, the whole chain can be trivially replicated to anyone. Much of the blockchain-specific technology is about reaching consensus on who gets to execute transactions and append the results as the next record to the log.
“Smart contracts” are pieces of code written for an execution engine of the respective blockchain technology. The code is added to the blockchain, very similar to how “stored procedures” are added to other databases, and the code is therefore distributed to anyone participating in handling the chain. Afterwards, the smart contract can be invoked by ways of recording the input arguments as a pending transaction. The contract will then be executed by everyone wanting to settle the transaction, and the consensus algorithm’s “winner” will manifest the result on the blockchain.
This principle is fascinating to many, because the execution of smart contract transactions happens without the application-level issuer needing to worry about the how and where. Once a smart contract has been added to the chain, it’s addressed with a logical name, and execution can happen anywhere.
The tradeoff made in the blockchain is similar to replicated databases: its abstraction magic is realized through all data going everywhere and through the network relationships being configured out of the application’s sight. For smart contracts, the processing outcome of a transaction gets back to the issuer simply because everyone gets the result of the transaction. The result of the tradeoff is that it is quasi impossible to keep secrets secret and is the model is inherently limited in scale due to the exponential growth of transaction replication load. With partitioning, these limitations then simply apply to each partition.
In spite of these tradeoffs, interacting with objects through a database interface and addressing them logically without having to worry about the underlying network reality or protocols or location affinities is enormously attractive to many, and I believe it’s one of the main attractions of blockchain. It’s provides a convenient centralized view on a decentralized system.
The downside is that the magic is that is enabled by replicating all data everywhere, which is not an option for a lot of scenarios due to transfer capacities, transfer cost, transfer and processing latency requirements, privacy and trade secret protection, and other concerns.
Messaging and eventing emerged as tools to complement database infrastructures to address these concerns and to build bridges between heterogeneous applications. But while databases provide a convenient an complete abstraction of objects from the underlying network, messaging and eventing infrastructures and their addressing models are generally fairly entangled with details of the underlying IP network. Databases (“data at rest”) and messaging (“data in motion”) are mostly not at the same abstraction level in terms of addressing objects and destinations.
Addressing
For realizing a model where the public IP network primarily acts as the interconnection fabric between Userland islands, and where messages might also temporarily be held by intermediaries (like queues), we need an addressing model that also works independent of IP connectivity and that allows spanning routes across otherwise isolated networks.
How can a user of a mobile device app be consistently addressed in spite of the user running an instance of that app on each of four devices and those devices roam across networks? How can some specific service endpoint be addressed when it’s not only behind an application API gateway, but behind layers of such gateways?
And drilling further into systems, it should be really also be possible to externally address an actor inside an actor system or a particular digital component of a complex composite machine.
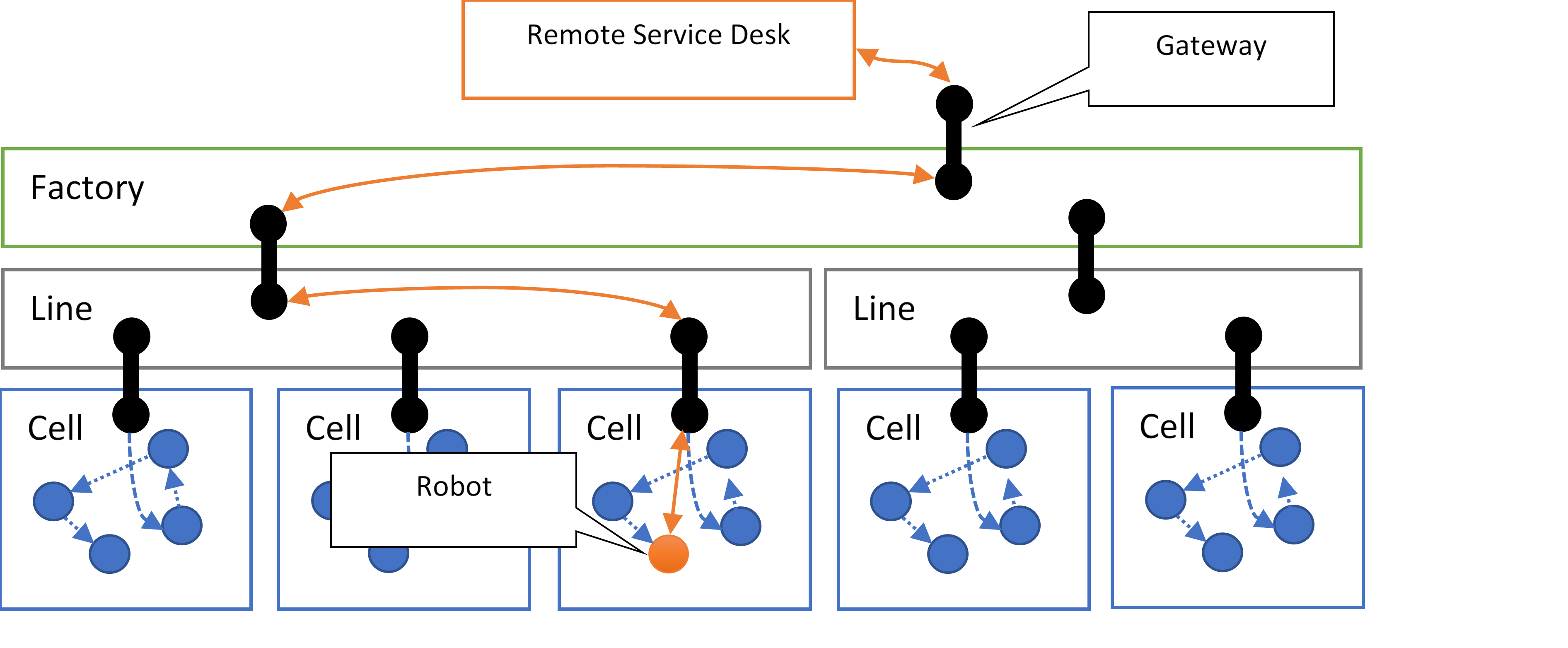
To give a more complex example, a manufacturing plant might use isolated IP network segments for each production cell allowing equipment inside the cell to communicate. The equipment inside the production cell might communicate using additional protocols and bus systems, with some of them possibly not having caught up to the state of the art on security best practices or where keeping those systems up-to-date is problematic for operational reasons.
Outside access to resources in the cell-level IP network might only be possible through a gateway device with dual network interfaces, functionally acting as an “air gap” for IP traffic, because IP-level access to such equipment potentially opens up a large attack surface area, and unauthorized access and manipulations may result in safety hazards that could get people killed and equipment destroyed.
The outside interfaces of cell gateways might reside on an isolated IP network for the respective factory production line, along with the respective control and supervision systems, and that network may then again have a gateway facilitating communication with systems at the factory level.
The network segmentation employed in such scenarios makes it intentionally impossible to establish an IP route to a robot inside a production cell, either from the production line or factory level or from the robot manufacturer’s remote servicing systems.
In spite of the IP networks being isolated, an addressing model for such an environment should still make it possible for gateways to securely route application-level messages from the robot manufacturer’s remote servicing desk to the robot and back, across the boundaries of isolated IP networks, potentially with extra reliability through intermediate queues, without exposing unsecured or vulnerable network assets, and while enabling the information flow to be inspected by intermediaries and logged in audit trails. And just like with NATs, the origins of routed traffic might have to be masqueraded similar to how Network Address Translation (NAT) performs it for IP, protecting sender privacy and preventing discovery of routing topologies by receivers not privileged to such information. The robot manufacturer might be authorized to see information about the robot, but it’s not necessarily authorized to discover the entire factory routing topology.
Scopes
My proposal for an addressing model that allows for constructing such routes has a very familiar look to it.
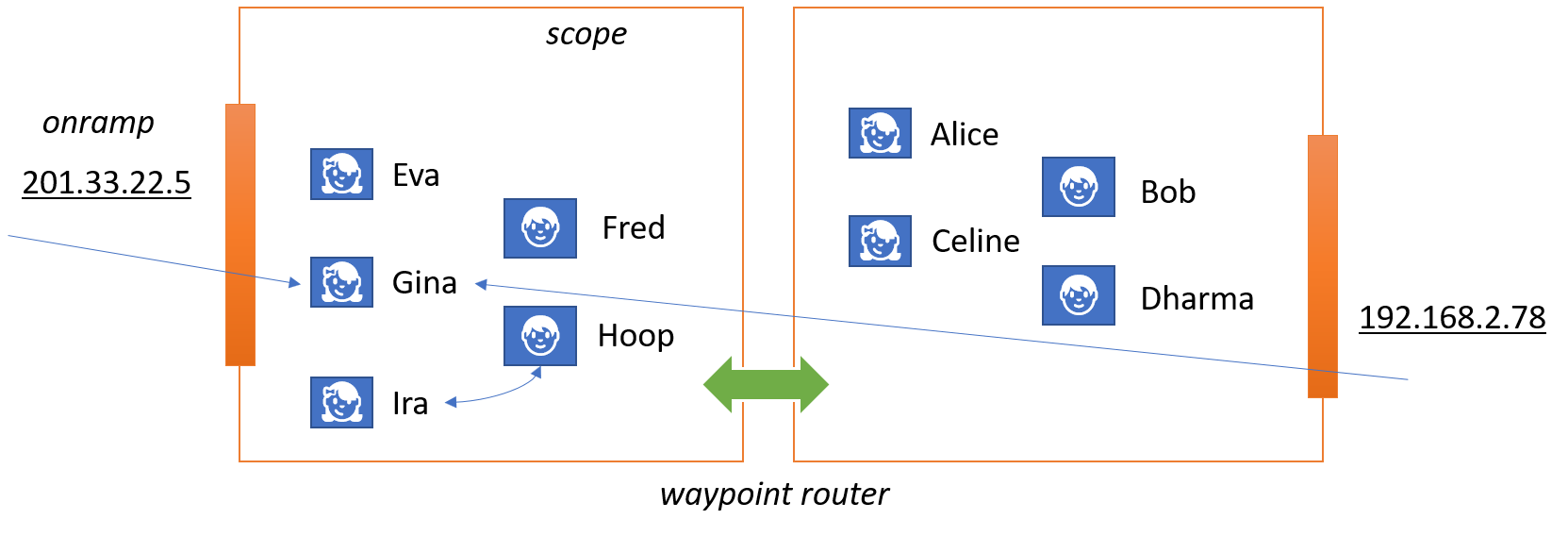
An scope identifier is a structured name for a routing target or source. scope identifiers are strings that follow the DNS naming conventions, but scopes do not have to be registered in DNS and they don’t have an associated IP address. They are just names abstractly describing places in a system, and the DNS-like structure helps expressing hierarchical relationships.
The term scope reflects that the addressed place might have further, addressable internal structure. It’s a space, not a point.
Scopes are intentionally decoupled from the IP network layer, because routes spanning scopes are meant to explicitly form a routing layer above it.
To get a tad bit more technical, this means that if an scope identifier is registered in DNS, any A or AAAA records will be meaningless and must be ignored. The only record type that might be used by a client is the SRV resource record type, which indicates a preferred IP “onramp” endpoint into the routing network.
Such an onramp endpoint might speak HTTP and/or MQTT and/or AMQP and/or some other application protocol, and its role is to get the event or message or request underway on its route towards the target scope. For a request/response interaction pattern as it’s typical with HTTP or RPC protocols, the onramp endpoint is obviously also responsible for taking care of establishing a return route and correlating an eventual response to the request and responding appropriately.
When mapped to URIs, the difference between onramp and scope is expressed by including two addresses. The onramp uses the common URI authority portion, and the scope uses a specially formatted expression in the first path segment. If the scope expression is absent or empty, the scope will be determined by the host. In the coming AMQP Addressing specification which will include scopes as a concept, it will look like this:

Putting the scope identifier in parentheses inside of a path segment may look a little odd, but it cleanly delineates the address, and it’s indeed odd enough to have minimal risk of clashing with existing usage. The same model can be used with other transports, including HTTP. Teaching a web server to seek the relative path root after the scope expression is not particularly difficult.
When routing inside the logical network, the onramp address is not required, and with the aforementioned DNS SRV record registrations, onramps can be supplied through DNS. Therefore, a purely logical address might take the following form:
target:(fred.contoso.com)/mailbox
The proposed abstract “target” URI scheme is a transport independent logical target address. The AMQP specification will use the amqp schema for the same expression and implementations may permit both.
A logical address may can also identify a context to subscribe from. Thus the subscription point for telemetry emitted by a device, and that qualifies all events emitted by the device might be:
source:(device672.site67.contoso.com)/temperature
The routing layer forms its own network. Think of it as roughly equivalent to a road or rail network with waypoints interconnected by links that are established over underlying IP networks, or messaging/eventing infrastructures, or other types of networks like industrial field-bus systems.
In the aforementioned factory-scenario, the gateways at the production cell and line and factory levels would take on the role of waypoints and are interconnected by links realized over the respective network segment that they both share. A link may be a permanent peer-to-peer multiplexed connection realized over a suitable protocol, or it might create single-use TCP connections on demand, or it might utilize some middleware.
The reason I don’t call waypoints “routers” here is that they are applications in their own right and that they are an explicit part of the solution. They’re not just some networking gear that makes sense out of numbers and ports. Waypoints choose target links to the next waypoint or the ultimate destination by considering addressing metadata or even content of a message, along with auxiliary information. The logic may lean on the current state of business processes or system capacities, may take into account that target scopes are not bound to physical locations, and may be predictive and adaptive using AI algorithms. In short, routing is elevated from a network function to an application function.

The scope is also an abstraction in the sense that it designates a place for where messages ought to be delivered rather than where the message consumer resides. With IP based addressing, there’s no way to identify an intended target that’s disconnected from the network or fenced off in an isolated address space.
A scope may function as a rendezvous location, providing a queue or a connection relay, where messages are being delivered to and held, and from which the designated receiver, picks them up coming from behind a NAT or later as it is able to establish a connection.
This addressing model also composes excellently with the “publish-subscribe” pattern. With publish and subscribe infrastructures, a producer publishes events without a specific intended target, but rather makes them available to an audience interested subscribers. A subscriber registers interest with a point of subscription and subsequently gets a copy of the published event delivered.
With an abstract addressing model, the point of subscription becomes location-agile.
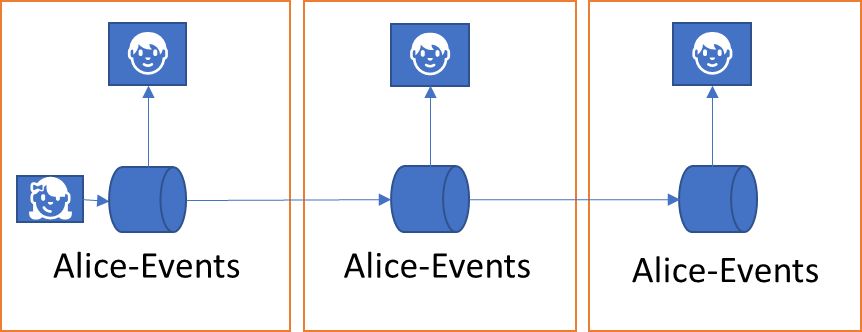
Whether the point of subscription resides right with the producer of message or events, like right on a sensor device, or whether the point of subscription has been delegated to some middleware is a flexible choice and might indeed change. A system might also implement subscription management such that the published event stream is distributed in the system and then available for subscribers in multiple different locations but all under the same logical name. That means that I can tap into a sensor data stream right on the sensor under a logical name, and I can use that same name for the same stream to tap into a stream replica in a cloud system, that’s “on the way” from the subscriber to the sensor, and the subscriber will not be able to tell the difference.
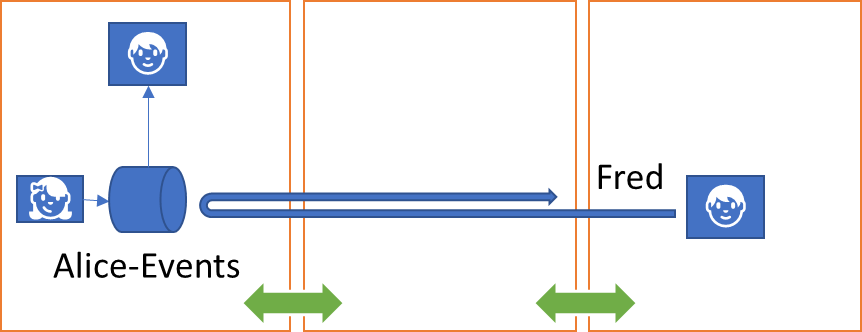
For a subscriber having its selected events delivered by the point of subscription in a “push” fashion, the subscriber needs to designate a delivery destination in form of a target scope. With the addressing model presented here, that destination may be several routing hops away and inside an isolated IP network or the destination might be a queue, or some device on a field bus.
There are multiple options for how an implementation of this model allow for the subscriber to be reachable via routes even without any prior relationship.
For instance, the trail of waypoints traversed during routing of the subscription operation can be annotated on the command message, and those annotation trails can then be turned into a “source route” annotation for delivery that the waypoints follow.
This can include masquerading whereby each waypoint encrypts the existing annotation trail as it hands the information forward. In our factory scenario, this would prevent a sensor manufacturer receiving maintenance telemetry from its devices to discover the full internal routing topology of the manufacturing plant by side effect.
Alternatively, the system might establish routing tables that keep track of the link(s) through which a subscriber is reachable at every waypoint. Those routing table entries may have an associated absolute-time or idle-time based expiration. This model also allows for stream duplication during distribution, because an implementation might provide a policy to route copies to all links registered for the same destination.
Creating and securing links and routes
A route associates a scope with a link connecting one Waypoint to another. The route may carry further metadata, such as cost information for making routing decisions.
Links and routes are directional. Route are registered with the sender side of a link and determine which messages are eligible for transfer on the link.
Even if the underlying transport’s communication transport for the link is bi-directional and allows for link multiplexing, the decision of whether replies to requests do indeed take the same return path is explicit. In situations where the issuer of a request is physically moving and potentially roaming across different networks, it might designate a queue as the reply target even if the request was routed direct.
A link needs to be established when there’s at least one active route, and the link can be dropped when there’s no more active route. For resource optimization, the communication path for links may be lazy-created as the first message appears and may be discarded after some idle time, but the link logically remains while routes exist.
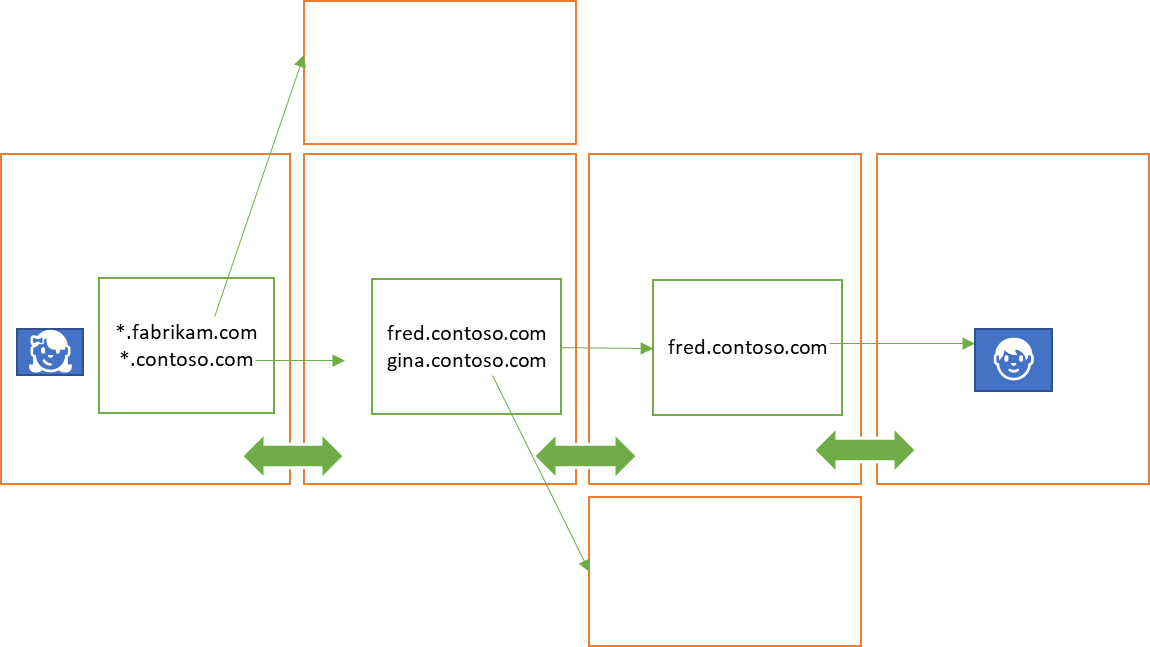
A network forms by scopes (including other waypoints) telling waypoints about themselves and how they can be reached, resulting in an entry in the routing table, which somewhat echoes the role of the Border Gateway Protocol (BGP) in IP networks.
Using a wildcard expression like *.services.vasters.com, a scope may register a route that covers all subordinate scopes covered bz the wildcard. A route with a lone asterisk as wildcard can only be administratively registered and is functionally equivalent to the default gateway in IP networks. Unless different prioritization criteria are used, the longest suffix matching a target determines the chosen route.
The security model for routes is based on “routing tokens”. When registering a route and also when annotating a message with a waypoint trail, the registering party must prove that it is the legitimate owner of its scope name. The model leans on the same principle as TLS server authentication.
A scope owner can prove its legitimacy by proving being in possession of the private key for a matching PKI certificate issued for the scope identifier in its subject, and with the certificate signature being chained up to a trusted root. The proof is a signature of the route registration record with the private key, and the signed, public certificate may be included with the registration that also carries the signature. Alternatively, the registration record may carry a token issued by a trusted third party that affirms the ownership of scope name in a signed claim, with the audience of the token being the designated waypoint.
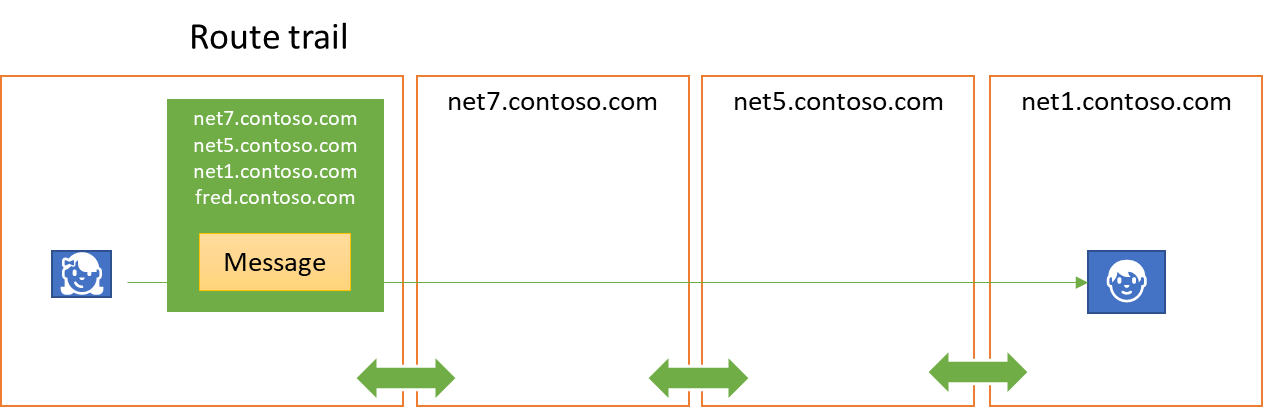
A route trail is created by chaining these tokens. A waypoint that receives an annotation trail which must be forwarded to yet another waypoint will sign the trail issued for it after adding itself to the list. The signature may again be performed based on a certificate or by an authentication authority.
A routing token not only confirms that the registered scope is legitimate, but it reversely also grants its bearer the permission to use the route. A routing token might have a set expiration, and might even include a filter condition that makes the routing token only valid for messages fitting the criteria. With this, it’s not only possible to constrain a route registration to a particular time window, but a reply route can even be constrained to only allowing replies with a specific correlation identifier. It’s also feasible for a routing token to carry a credit for routing a specific number of messages, and that the token is considered expired and discarded by a waypoint when the credits are used up.
A system may demand a fully verifiable route trail for all waypoints or may permit routing based on a partial route trail, including one that only covers the last hop.
Making it real
In the OASIS AMQP Technical Committee, we will add the abstract notion of scope into the addressing specification within the very near future. A complementing routing specification will describe further details of the model as described here, but priorities demand for some other specifications to be written, reviewed and discussed first.
The model described here will be most useful if it’s not only applied to AMQP, but if there are mappings for HTTP and MQTT and Kafka and other protocols, so that routing is not only possible over multiple hops but also across different protocols, utilizing existing infrastructures that already straddle IP network boundaries today. Those mappings will have to describe how logical and routable addressing fits with those protocols’ own addressing constructs.
I am very interested in feedback and collaboration proposals for this abstract model. Since this is a higher level abstraction similar to the work I participate in the CNCF CloudEvents project, it may makes sense to assemble a similar cross-company working group to see where we can take this if you were interested. I can be reached via Twitter @clemensv or via my work email address clemensv@microsoft.com